Episode 168
| May 01, 2019
| 20 minutes
Data Privacy Settings
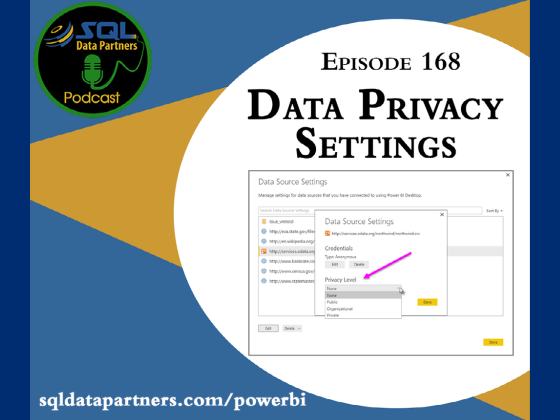
One of the great abilities we have with Power BI is connecting to multiple data sources. Authors can actually publish data sources for others to use in their reports. Developers then get to mix and match our reports with all that data; however, there will be times we don’t want everyone to see all the data sources. In today’s episode, we discuss Power BI privacy levels, what they are and what they can–and can’t do for you.
Episode Quotes
“Data Privacy levels affect whether query folding happens with your data sources, and that’s it. It doesn’t affect who can see what, it doesn’t affect security, it doesn’t affect anything else. All that it affects is query folding.”
“It’s not going to fold organizational information into your queries towards a public source and it’s not going to fold private information into queries towards organizational or public sources.”
“My baseline recommendation is, if it’s anything internal, mark it as organizational and if it’s anything external, mark it as public.”
Listen to Learn
00:38 Intro to the team & topic
01:08 Compañero Shout-Outs & recording from Mala
03:59 SQL Trail Information & request for opinions
05:25 SQL Server in the News
06:37 Data privacy levels only affect query folding
08:24 Explanation of what query folding is – hint: it’s not KonMari
10:52 Sometimes query folding is too smart
12:41 The three tiers of privacy levels
13:20 The “hey, ignore all of this” gateway – potential performance improvement
15:24 Eugene’s advice on how to mark your data
17:09 Read Microsoft’s security whitepaper
17:55 You have to set levels yourself or ‘none’ is the default setting
18:32 Kevin’s 10 second summary of this episode
19:04 Closing Thoughts
Credits
Music for SQL Server in the News by Mansardian
Meet the Hosts

Carlos Chacon
With more than 10 years of working with SQL Server, Carlos helps businesses ensure their SQL Server environments meet their users’ expectations. He can provide insights on performance, migrations, and disaster recovery. He is also active in the SQL Server community and regularly speaks at user group meetings and conferences. He helps support the free database monitoring tool found at databasehealth.com and provides training through SQL Trail events.

Eugene Meidinger
Eugene works as an independent BI consultant and Pluralsight author, specializing in Power BI and the Azure Data Platform. He has been working with data for over 8 years and speaks regularly at user groups and conferences. He also helps run the GroupBy online conference.

Kevin Feasel
Kevin is a Microsoft Data Platform MVP and proprietor of Catallaxy Services, LLC, where he specializes in T-SQL development, machine learning, and pulling rabbits out of hats on demand. He is the lead contributor to Curated SQL, president of the Triangle Area SQL Server Users Group, and author of the books PolyBase Revealed (Apress, 2020) and Finding Ghosts in Your Data: Anomaly Detection Techniques with Examples in Python (Apress, 2022). A resident of Durham, North Carolina, he can be found cycling the trails along the triangle whenever the weather's nice enough.
Want to Submit Some Feedback?
Did we miss something or not quite get it right? Want to be a guest or suggest a guest/topic for the podcast?